So what exactly is a Federated Partition? I can find no documentation on them (with the exception of the RealtimeCSV_Updates.xlsx file in the Cloud Gallery). They were briefly presented by Oracle at Kscope19. My only understanding comes from trying to set them up and speaking directly with Oracle product management.
Very simply put they are transparent partitions to either relational databases or flat files. The data is not stored in Essbase, it remains in the source. "Realtime Partitions" is how they were presented at Kscope19.
This architecture has a number of ramifications I'm sure. The word "fast" does not come to mind but the jury is still out.
Now I'll walk through creating one in Essbase 19c. I tried getting this to work in OAC back when OAC meant Essbase Cloud but ran into many issues and was not successful. This is going to be a very simple example using a flat file source. When the data in that flat file changes, the data in Essbase will change -- like magic. Yeah, mind blown, I know, let's get started...
Create the Cube and Partition
Essbase 19c comes with a gallery of applications well beyond Sample Basic. The one designed to demonstrate Federated Partitions is called RealtimeCSV.
Import the cube from the Gallery.

Select the RealtimeCSV_Updates.xlsx file which contains everything Essbase needs to build the cube.
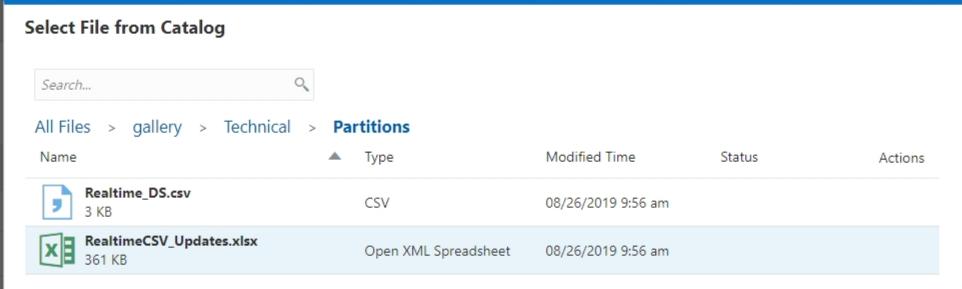
Now I can see cube in my list of applications.
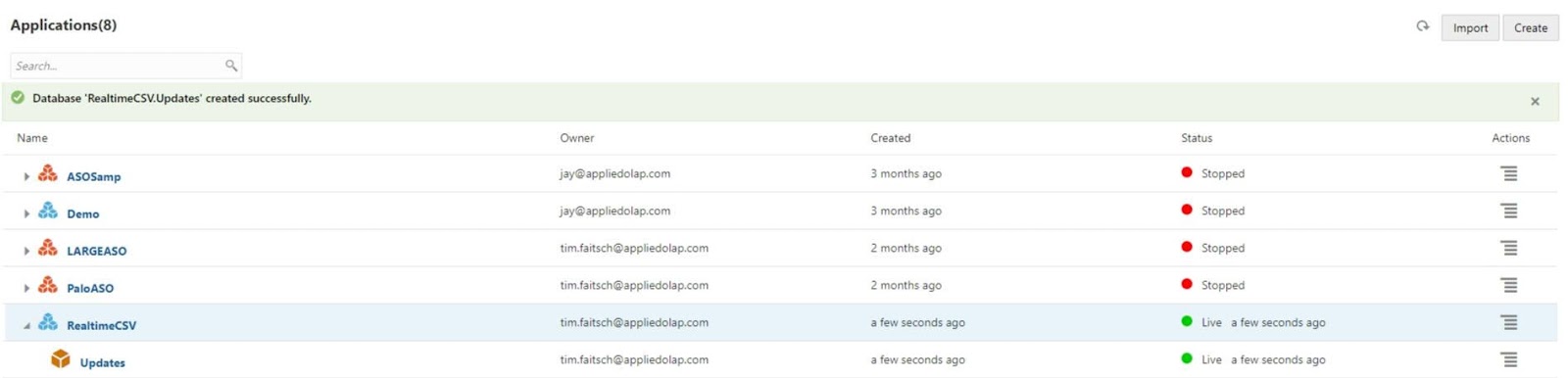
Under Sources, I select Create Connection and File.
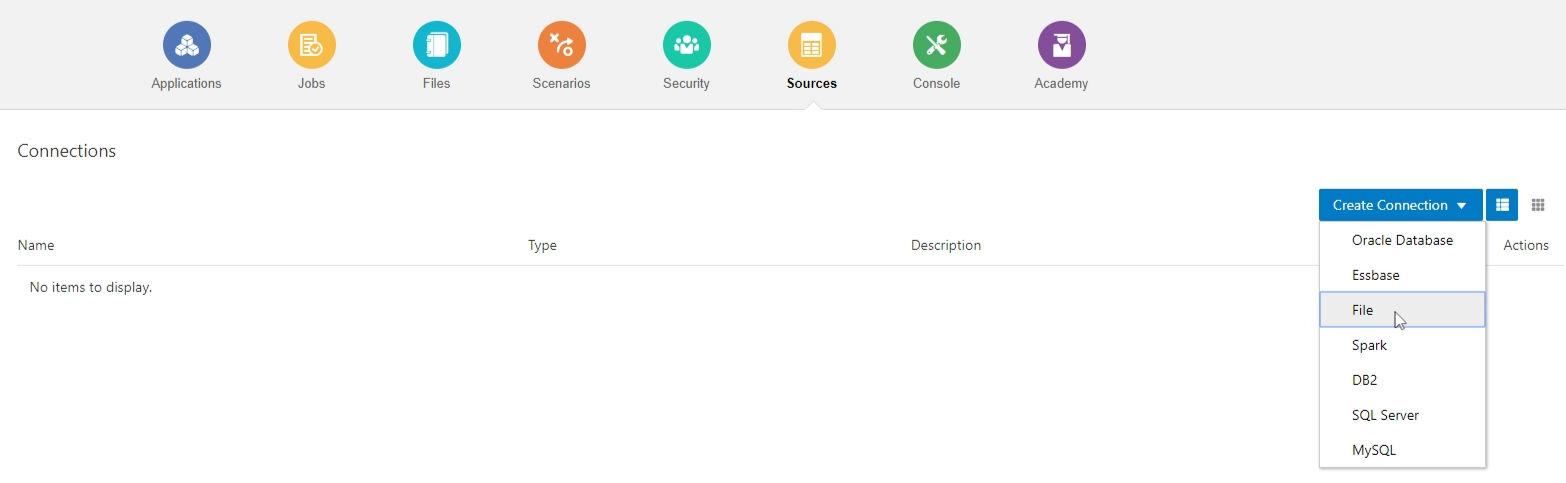
I named my connection RealTimeCSV_Conn and selected the Realtime_DS.csv file from the shared folder on the cloud. Since you cannot update the files in the Gallery, I made a copy of the Realtime_DS.csv file which will allow me to update it.
Next I selected Datasources and Create Datasource. Then I chose the Connection I just created.
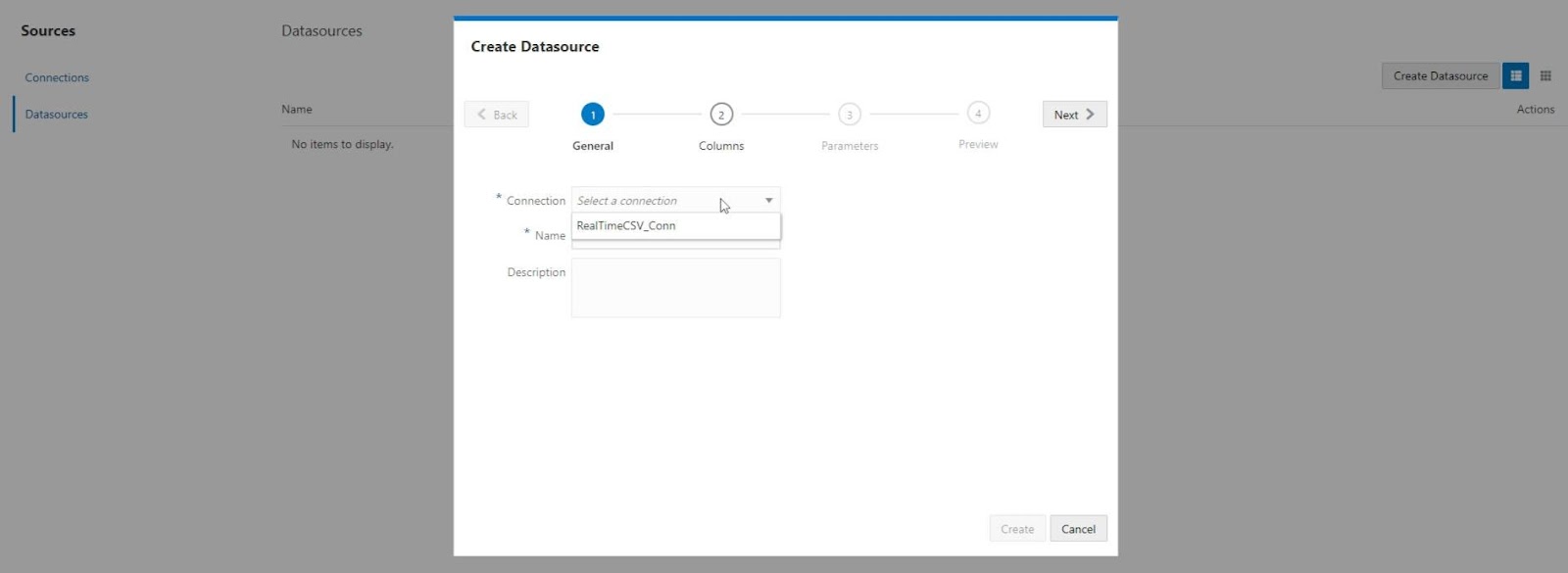
I named the Datasource RealtimeCSV_Conn and clicked Next.
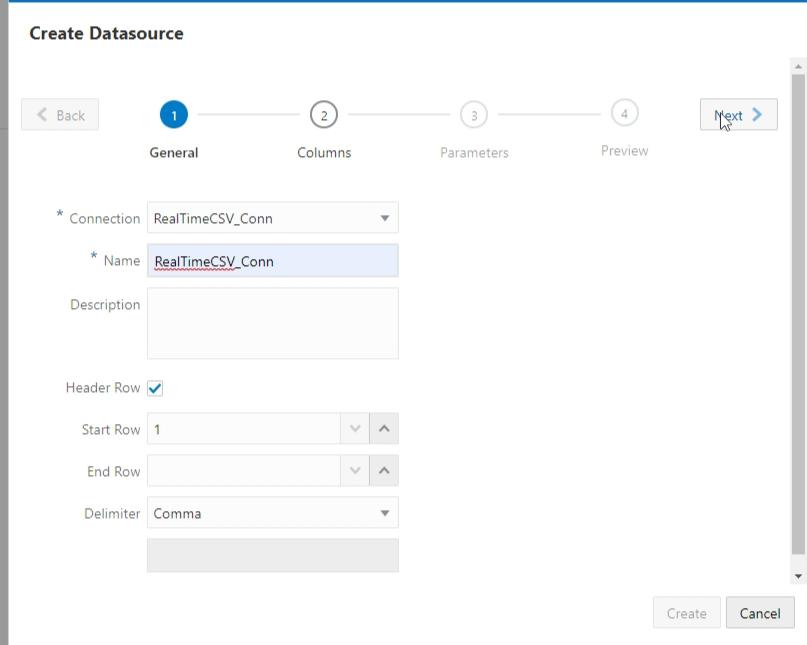
I changed the Units and Price column to have the Double type. Then clicked Next.
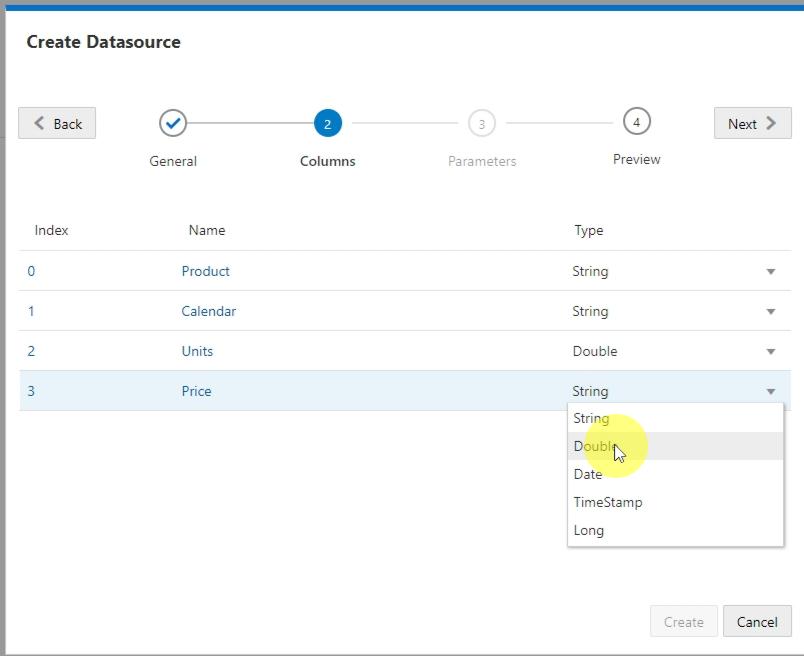
Finally I was prompted with a Preview of my data and I clicked Create.
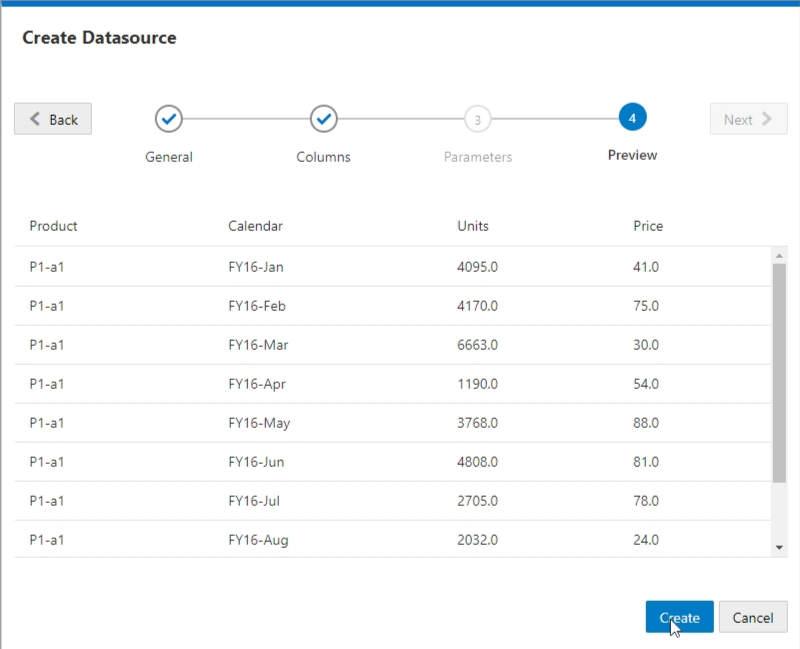
Next I clicked on the Areas tab. From there I clicked the Add Area button and entered my Target Area using Essbase functions and member names.
I then clicked the Validate button followed by the Save and Close button.

I then went to pull in some data to test the cube. The data is coming into this cube in real time.
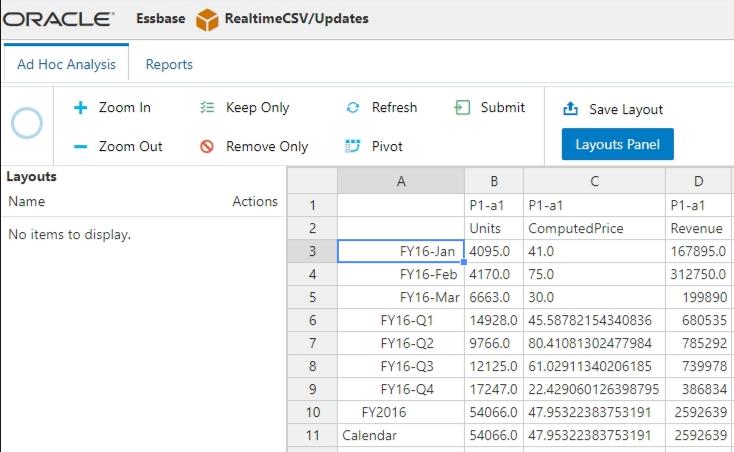
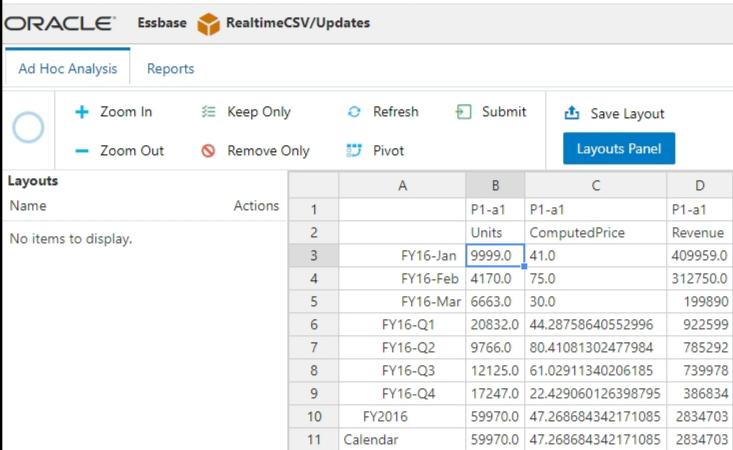
Finally, I went back and updated the csv file with some different numbers. I refreshed my data and the changes were reflected.
Just to prove what's going on here, I'll show you the database storage statistics. You can see that there are no blocks and no pag or ind files.

Speculating Wildly
So what does this all mean? Why would Oracle be spending time on a feature like this? All of this is speculation influenced by comments I've heard from product managers over the past year...Oracle is a database company. They make a really powerful database that runs a significant portion of the world. Wouldn't it be really cool if they could scrap page and index files altogether and just have their relational database store all of the level 0 Essbase data? Well that's what this is. Right now. Slap hybrid calculations on top and you have real-time updates to your cube. No loads, no calcs.
It always comes down to performance. This cube is three dimensions. It's got training wheels and makes Sample Basic look complicated. I'll remain skeptical, outside of small use cases, until I see large cubes using Federated Partitions with sizable data sources. In the meantime it's another tool in the toolbox. Drop me a line if you start using it in a production environment.
1 comment:
I have been searching for such an informative publication for many days, and it seems that my search here has just ended. Good job. Continue publishing.
room dividers in dubai,glass partitions,glass partitions in dubai
Post a Comment